GeoTIFFs to GPUs part 1: An Unexpected Conflict - multi-threaded reads, too many jobs
In a corner of a world, there lived a kiwi. Not exactly a corner, since the world is round and corners don't exist on spheres, nor is it not a corner as people do leave it off maps sometimes. It was a kiwi-corner, and that means comfort.
I love GeoTIFFs, they're the one reliable raster format I can drag and drop into QGIS to open out of the box. NetCDF? only if it conforms to some convention. GeoZarr? good luck with that. GeoTIFFs though, they are comforting, they just work.
Yet something I've been fighting for since 2023, maybe earlier, was to get reasonable read speeds out of GeoTIFFs, specifically Cloud-Optimized GeoTIFFs (COGs) that supposedly have a better internal layout. The defacto way to read GeoTIFFs is through a 20+ year old C/C++ library called GDAL (technically wrapping libgeotiff). GeoTIFFs/COGs are by far the most popular raster file format according to GDAL's 2024 user survey.

GDAL is usually great, and if you're using GDAL 3.10+, RFC 101 read-only thread-safety should now be implemented, and that works in theory if using GDAL standalone. The problem with GDAL (or any C/C++ library that does parallelism) is when you try to use its parallel mode with another library that also has some form of parallelism.
This is summed up really nicely by Ralf Gommers in this discussion thread:
Some libraries, like the deep learning frameworks, do auto-parallelization. Most non deep learning libraries do not do this. When a single library or framework is used to execute an end user program, auto-parallelization is usually a good thing to have. It uses all available hardware resources in an optimal fashion.
Problems can occur when multiple libraries are involved. What often happens is oversubscription of resources. For example, if an end user would write code using scikit-learn with n_jobs=-1, and NumPy would auto-parallelize operations, then scikit-learn will use N processes (on an N-core machine) and NumPy will use N threads per process - leading to N^2 threads being used. On machines with a large number of cores, the overhead of this quickly becomes problematic ...
So this means that it has been incredibly hard to use TIFFs for machine learning workflows. For example:
- Using GDAL (or any library that wraps it like
rasterio,rioxarray) with multi-threading + Pytorch multi-processing withnum_workers>=1can cause trouble (e.g. https://github.com/microsoft/torchgeo/discussions/594) - Using
tifffile(a pure-Python TIFF libary) which has/had built-in auto-parallelization conflicts with threading from scikit-learn (https://github.com/cgohlke/tifffile/issues/215).
And this is very sad, it means lots of wasted effort spent on debugging and workarounds. You might try a bunch of environment variables in GDAL, OpenMP, etc, and kudos to you if you manage to figure it out (if not, this paper has some great insights)! But most people would eventually give up and resort to one of two options:
- Convert the GeoTIFFs to another format.
- Find a different library, discover that most everything uses GDAL under the hood, and give up (or write your own!).
Side note: The ideal solution for this is definitely some protocol around distributed/parallel conventions, xref https://github.com/data-apis/array-api/discussions/776, but that is a whole other can of worms that extends beyond GeoTIFFs to parallel computing in general.
1. Convert from GeoTIFF to format X
For a while, I've been advocating for Zarr (e.g. here), and this is worth it if you have >3 dimensions and/or many data variables (e.g. time-series, simulation model outputs). Other formats people have tried include:
- Binary formats like NPY/NPZ files, TFRecord, etc
- Putting rasters in tables (why?!!) like MajorTOM, whose reference implementation is essentially a Parquet table with image data stored as PNG bytes, or Havasu which sits on top of Apache Iceberg
- Sharded file formats like webdataset, Mosaic Data Shard (MDS), litdata, etc
Quite often, in the midst of this conversion, people will split the big GeoTIFF (say 10000 x 10000 pixels) into smaller tiles or 'chips', of say 512 x 512 pixels. I've done it here, others have done it here, here and here. It's one of those wheels that keeps getting reinvented over and over again.
But look inside a Cloud-optimized GeoTIFF, the data is already stored as groups of tiles!
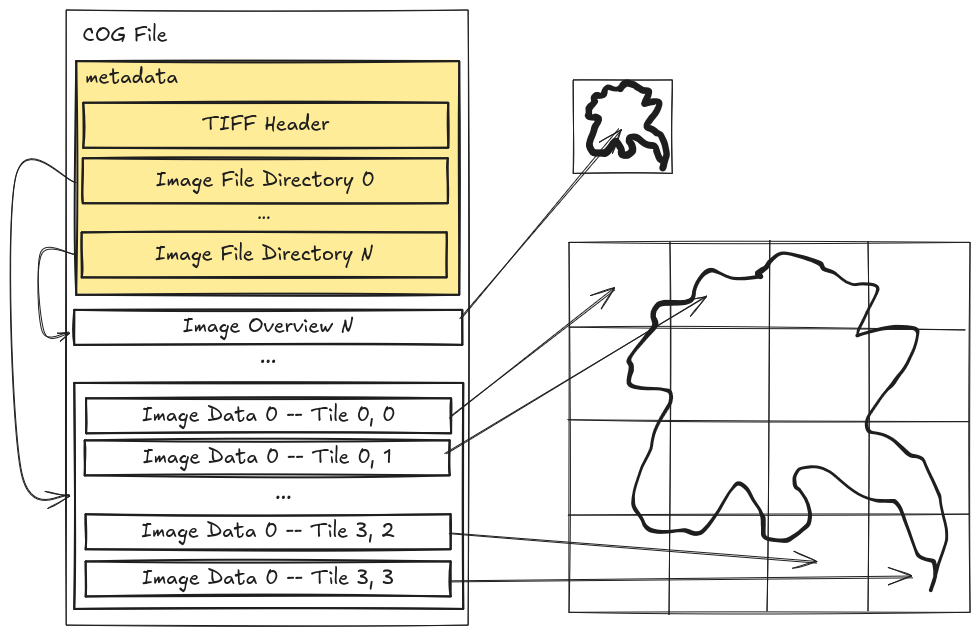
We are duplicating data to workaround limitations in the I/O libraries not playing nicely with other parallel libraries. We are also usually throwing away most of the nice metadata that describes the GeoTIFF, things like projection systems, spatial resolution, etc. So bad, it's so bad.
What if we don't want or need to reformat the data? What if we want to keep the CoG?
2. Use another library
I'll admit, it is hard to replace a 20+ year old C library seen as the defacto standard for reading/writing GeoTIFFs. But I'm encouraged by similar parallels happening in the HDF5 world, summed up nicely on this page:
... All of these approaches revolve around either changing the data, or supplementing the data with additional tools and metadata.
This article recommends a different approach: change the library.
Given that there is currently only a single implementation of the HDF5 format in use – the HDF5 library, it becomes the de facto standard, and the limitations of the library become the limitations of the format. If the library performs poorly in a cloud environment, it is said that the format is not suited to the cloud environment.
The format we have - Cloud-optimized GeoTIFF - is already pretty good, with a well written specification. Maybe we just need a different way to read it - not through multi-threading/multi-processing (parallelism), but via concurrency (asynchronous).
My colleagues at Development Seed have started some Rust-based efforts like async-tiff and virtual-tiff, based on pioneering work done using the Python-based aiocogeo.
These libraries are tackling the issue by going asynchronous (concurrency), which is different from multi-threading/multi-processing (parallelism) that hogs processor time.
See this comic - Concurrency and Burgers - for a good explainer.
Where asynchronous helps is at the I/O layer, such as when transferring data across the network, or reading raw bytes from disk. There is another layer that needs to be handled - decoding of raw bytes, typically compressed, into the actual numbers that have a physical meaning like elevation, reflectance, etc.
This decoding part is typically more CPU-bound, so even if we try to be smart with making things async (that is ok for IO-bound problems), we will still be bottlenecked by how many CPU cores are available.
So if we truly want to parallelize things, what is needed, is something that can handle high IO-throughput, and also has many cores. What we want to use is accelerated hardware.
Going GPU-native
Enter - nvTIFF - a GPU-accelerated TIFF encode/decode library built on the CUDA platform. It also integrates with nvCOMP, which means GPU-based decompression is possible! Doing more stuff on the GPU is great, it means we don't need to compete with threads/processes on the CPU.
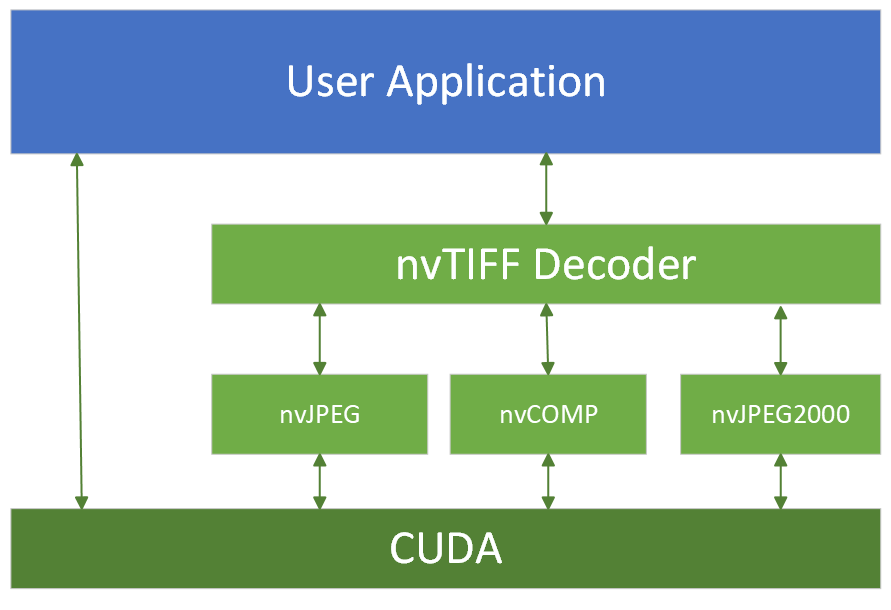
I've had my eyes set on nvTIFF since I happened upon it looking through nvImgCodec, and that's probably still the best way to access it. But nvImgCodec wraps too many things and is a somewhat high-level. I desire for something lighter, I wanted to play with the low-level stuff.
So here's my approach - create some lightweight bindings to nvTIFF (a C++ library) in Rust using rust-bindgen.
From Rust, I'll then create Python bindings via pyo3 in my cog3pio library that I've been using as a placeholder to become the next-gen GeoTIFF library.
Results are already promising, here's a sneak peek:

Benchmarks were ran on a 318MB Sentinel-2 True-Colour Image (TCI) Cloud-optimized GeoTIFF file (S2A_37MBV_20241029_0_L2A) with DEFLATE compression. You can find the code here, though it is still alpha-level quality.
Top row shows the GPU-based nvTIFF+nvCOMP taking about 0.35 seconds (~900MB/s throughput), compared to the CPU-based GDAL taking 1.05 seconds (~300MB/s throughput), and image-tiff taking 1.75 seconds (~180MB/s throughput).
These Cloud-optimized GeoTIFF reads were done reading from a local disk rather than the network.
Hardware details
- NVIDIA RTX A2000 8GB GPU, PCIe Gen 4.0 x8 lanes
- 12th Gen Intel Core i5-12600HX x16 cores
Do take this 3x speed up of nvTIFF over GDAL with a grain of salt. On one hand, I probably haven't optimized the GDAL or nvTIFF code that much yet. On the other hand, I haven't even included the CPU -> GPU transfer cost if I were using this for a machine learning workflow!
Summary + Next steps
For almost a decade, anyone trying to do massively parallel computations with GeoTIFFs have been relying on workaround upon workaround, ranging from format conversions to changing sub-optimal default settings and so on. Recent advances in GPU accelerated hardware and software has shown what is possible, we just need to figure out how to do things effectively.
I'm not saying that we should rewrite GDAL (in Rust), but if you'd like to join me in this journey, I'm proposing we build composable pieces to handle every layer of decoding a Cloud-optimized GeoTIFF:
- Network/Disk transfer - via
object_storeorkvikio Remote IO - Decompression of raw bytes - through
numcodecsornvcomp - Parsing of TIFF tag metadata - handled by
geotiffornvtiff-sys
The first two steps are general enough to be used by other data formats, Zarr, HDF5, etc.
It is only the third step - TIFF tag metadata parsing, which requires custom logic.
And maybe once we have a GDAL-less TIFF I/O reader, libraries like xarray-spatial can realize their true potential.
In our next post, we'll dive into the technical details of how nvTIFF can be wrapped via rust-bindgen, using that to decode GeoTIFFs into bytes on CUDA/GPU memory.
Follow along this trilogy!
- Part 1: An Unexpected Conflict - multi-threaded reads, too many jobs
- Part 2: Barrels Out of Bytes - streaming Rust bits to the GPU
- Part 3: The Last Stage - via DLPack into the world
P.S. This post has been shared to https://discourse.pangeo.io/t/decode-geotiff-to-gpu-memory/5214, and there are some insightful responses there you might be interested in!